type
Post
status
Published
date
Dec 21, 2021
slug
data_analysis_runboy
summary
一、概述
1.数据来源
本次数据分析使用的数据来源腾讯视频的《奔跑吧》第九季第八期的弹幕数据。
2.数据概述
数据格式为JSON格式数据,包含在回调函数中,需使用正则表达式提取出来后再进行后续数据分析操作
3.依赖包及格式文件介绍
requests库是一个常用的用于http请求的模块,它使用python语言编写,基于urllib,采用 Apache2 Licensed 开源协议的 HTTP 库,可以方便的对网页进行
tags
爬虫
数据分析
category
数据分析
icon
password
Property
Nov 16, 2022 09:10 AM
一、概述
1.数据来源
本次数据分析使用的数据来源腾讯视频的《奔跑吧》第九季第八期的弹幕数据。
2.数据概述
数据格式为JSON格式数据,包含在回调函数中,需使用正则表达式提取出来后再进行后续数据分析操作
3.依赖包及格式文件介绍
requests库是一个常用的用于http请求的模块,它使用python语言编写,基于urllib,采用 Apache2 Licensed 开源协议的 HTTP 库,可以方便的对网页进行爬取,相比urllib更加方便,可以节约开发者大量的工作,是学习python爬虫的较好的http请求模块。
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
jieba的主要功能是做中文分词,可以进行简单分词、并行分词、命令行分词,当然它的功能不限于此,目前还支持关键词提取、词性标注、词位置查询等。
wordcloud是优秀的词云展示第三方库,以词语为基本单位,通过图形可视化的方式,更加直观和艺术的展示文本。
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写,JSON对象由花括号括起来的逗号分割的成员构成,成员是字符串键和上文所述的值由逗号分割的键值对组成。
CSV是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用,最广泛的应用是在程序之间转移表格数据,而这些程序本身是在不兼容的格式上进行操作的。下面展示的代码实现了JSON格式向CSV的转换。
二、弹幕数据分析及可视化
1.导入全部依赖包
import requests import re import json import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt import pandas as pd
2.设置matplotlib中文字体
plt.rcParams['font.sans-serif'] = ['simhei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
3.通过requests来获取弹幕内容数据
url = '<https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109073533539243266_1625488331995&target_id=6972946900%26vid%3Dq00389hmv7w&session_key=0%2C0%2C0×tamp=15&_=1625488331996>' response = requests.get(url) response.encoding = 'utf-8'
4.从包含回调函数的字符串中提取JSON格式内容数据
main_json = re.findall('jQuery\\d+_\\d+[(](.*)[)]',response.text)
5.加载JSON数据解析并进行数据整理
js = json.loads(main_json[0]) danmu = [''.join(item['content'].split()) for item in js['comments']] data = [[item['timepoint'],''.join(item['content'].split())] for item in js['comments']]
6.保存数据到CSV文件中
def save_csv(data): for item in data: with open('danmu.csv','a',encoding='utf-8') as f: f.write(','.join([str(i) for i in item])+'\\n')
7.统计弹幕词频并绘图
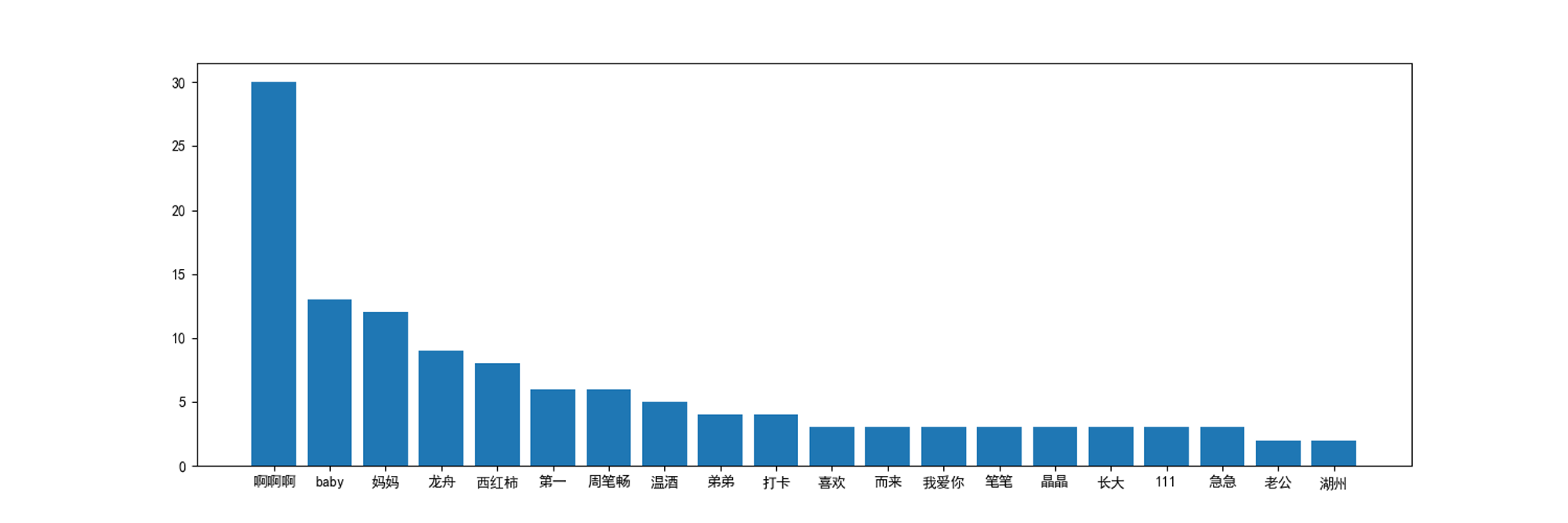
words = jieba.cut(' '.join(danmu),cut_all=True) words = movestopwords(words) word_hot={} #统计词频 for i in words: if len(str(i))>1: word_hot[i] = word_hot.get(i,0)+1 # 词频按从大到小进行排序 word_hot = sorted(word_hot.items(), key=lambda d: d[1], reverse=True)[:20] word_hot = [[i[0] for i in word_hot],[i[1] for i in word_hot]] plt.figure(figsize=(15,5)) plt.bar(word_hot[0],word_hot[1]) plt.show()
8.绘制词云图
wc = WordCloud( font_path='simhei.ttf', #字体路劲 background_color='white', #背景颜色 width=1000, height=600, max_font_size=300, #字体大小 min_font_size=10, max_words=100, collocations=False, font_step=1 ) #这里云图 传入数据必须是带有空格的才能识别 s=wc.generate(' '.join(words)) plt.figure(figsize=(10,6)) #必须有这个才会显示图 plt.imshow(s) #去除横纵坐标轴 plt.axis('off') plt.show()

9.统计弹幕中出现名字的数量并绘图
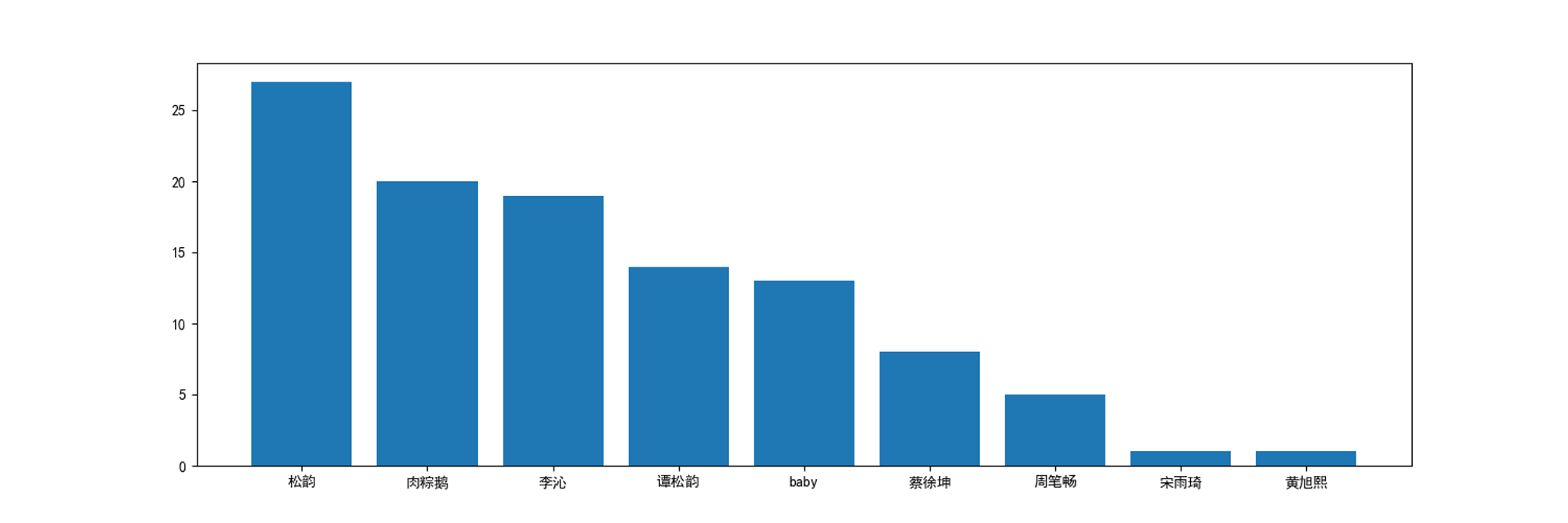
names = [ 'baby','周笔畅','蔡徐坤','李沁','宋雨琦','谭松韵','松韵','肉粽鹅','黄旭熙'] for name in names: jieba.add_word(name,freq=1) words = jieba.cut(' '.join(danmu)) words = movestopwords(words) word_hot = {} for i in names: word_hot[i] = words.count(i) word_hot = sorted(word_hot.items(), key=lambda d: d[1], reverse=True)[:20] word_hot = [[i[0] for i in word_hot],[i[1] for i in word_hot]] plt.figure(figsize=(15,5)) plt.bar(word_hot[0],word_hot[1]) plt.show() wc = WordCloud( font_path='simhei.ttf', #字体路劲 background_color='white', #背景颜色 width=1000, height=600, max_font_size=300, #字体大小 min_font_size=10, max_words=100, collocations=False, font_step=1 ) s=wc.generate(' '.join([item for item in words if item in names])) plt.figure(figsize=(10,6)) plt.imshow(s) plt.axis('off') plt.show()

10.统计时间上的弹幕分布
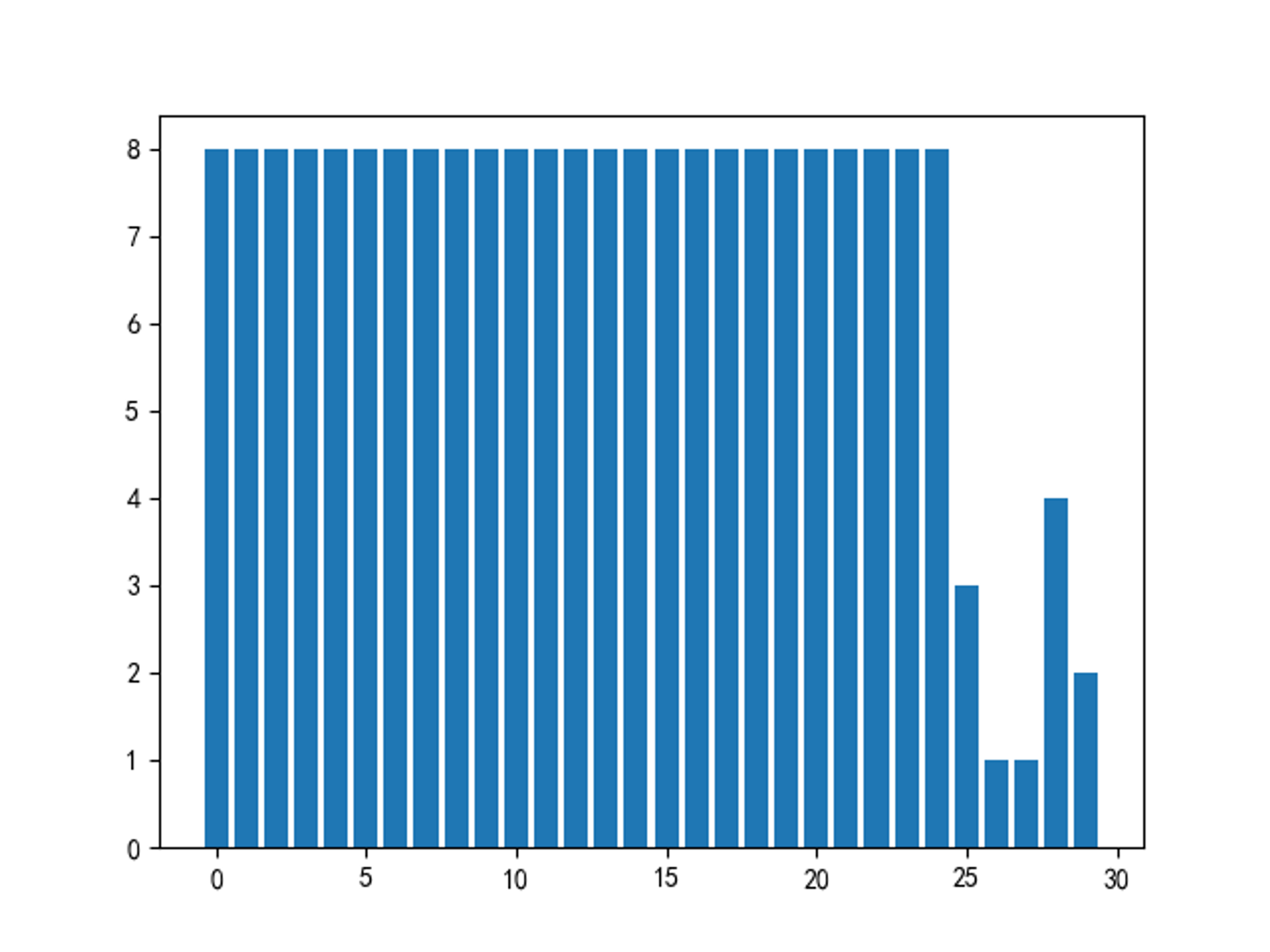
df = pd.read_csv('danmu.csv',names=['time','content']) time = range(30) count_df = df['time'].value_counts(sort=True) count_dic = dict(count_df.items()) count = [] for item in time: count.append(count_dic[item]) plt.bar(time,count) plt.show()
三、结论
通过对腾讯视频的《奔跑吧》第九季第八期的弹幕数据分析,统计并绘制了弹幕词频统计图、词云图,发现“啊啊啊”出现的频率最高,其次是“baby”;统计并绘制了名字频率统计图、词云图,发现“松韵”出现的频率最高为23次,其次为肉粽鹅,为20次;统计并绘制了各时间节点(timepoint)的弹幕密度,其中前二十四个时间节点的弹幕密度相同均为8,时间节点26、27弹幕密度最少为1。
- Author:Quanfita
- URL:https://quanfita.cn/article/data_analysis_runboy
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts
